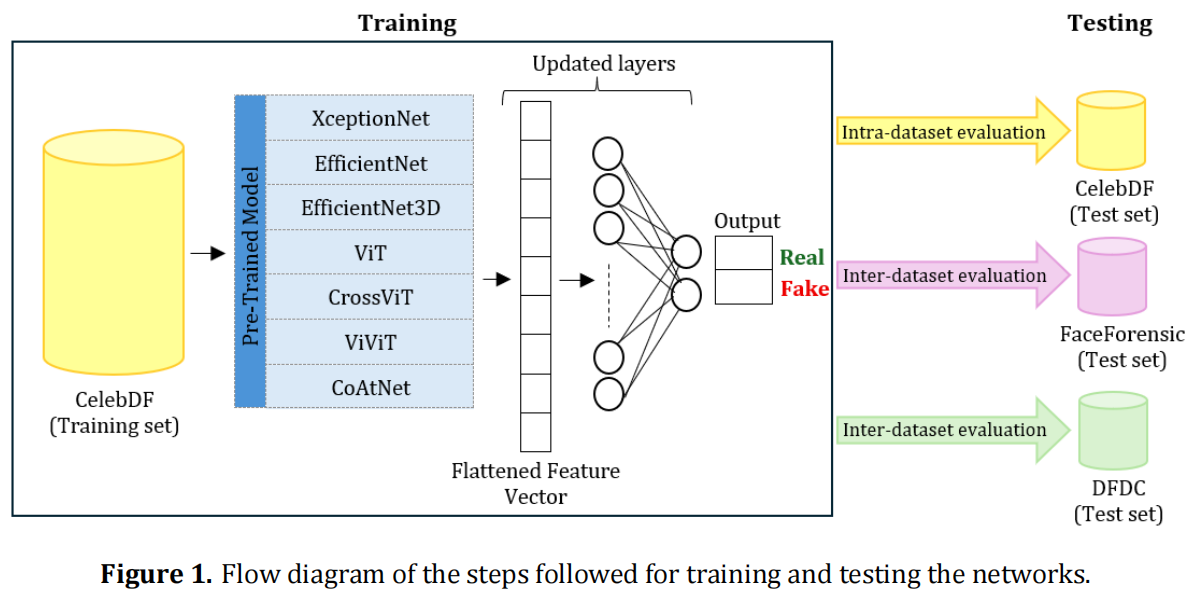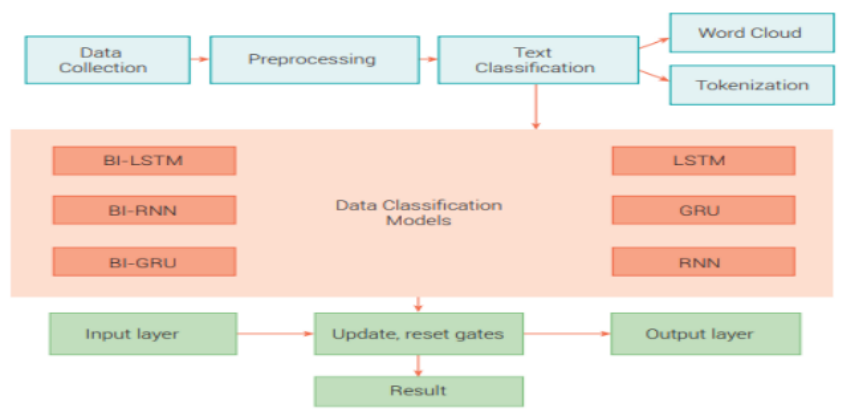

Digital Technologies Research and Applications
Digital Technologies Research and Applications (DTRA) is a peer-reviewed, open-access journal that provides researchers, scholars, scientists, and engineers worldwide with a platform for exchanging and disseminating theoretical and practice-oriented papers on digital technologies and their applications.
- ISSN: 2754-5687
- Frequency: Quarterly
- Language: English
- E-mail: dtra@ukscip.com
Indexing: Scopus, Google Scholar
Journal Abbreviation: Digit. Tech. Res. Appl.
Latest Published Articles
View all issues →
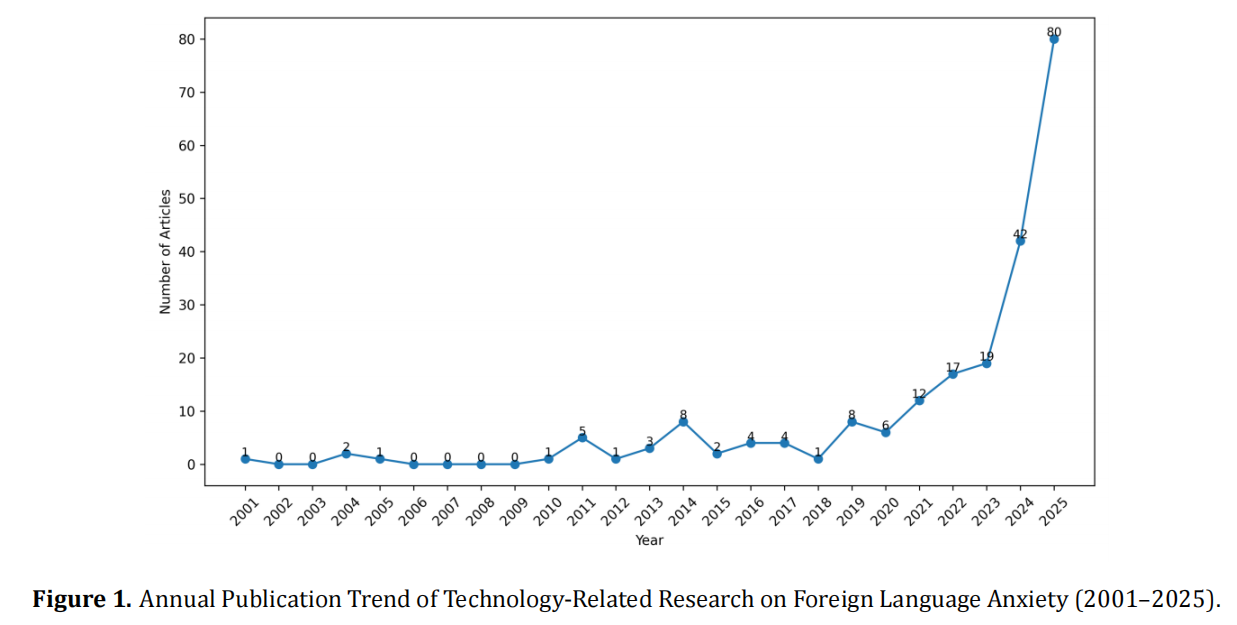
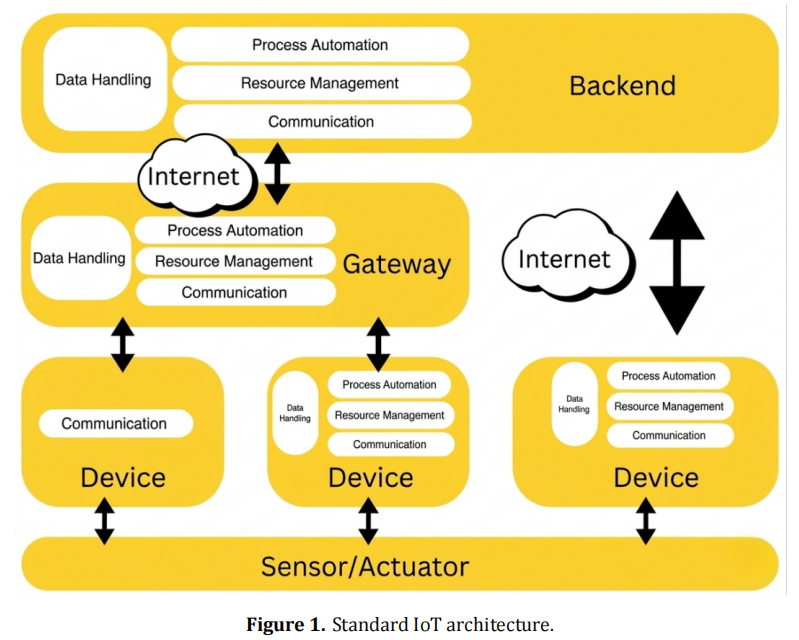
Article
Article ID: 102805
Insights into Digital Technologies Sustainability and the Economic Performance of Greek Enterprises