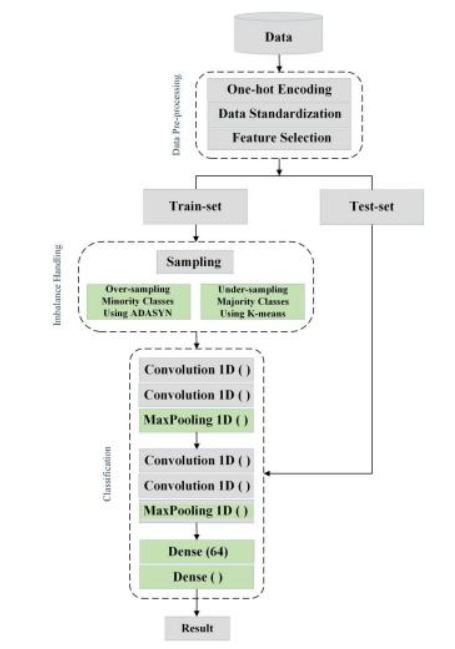
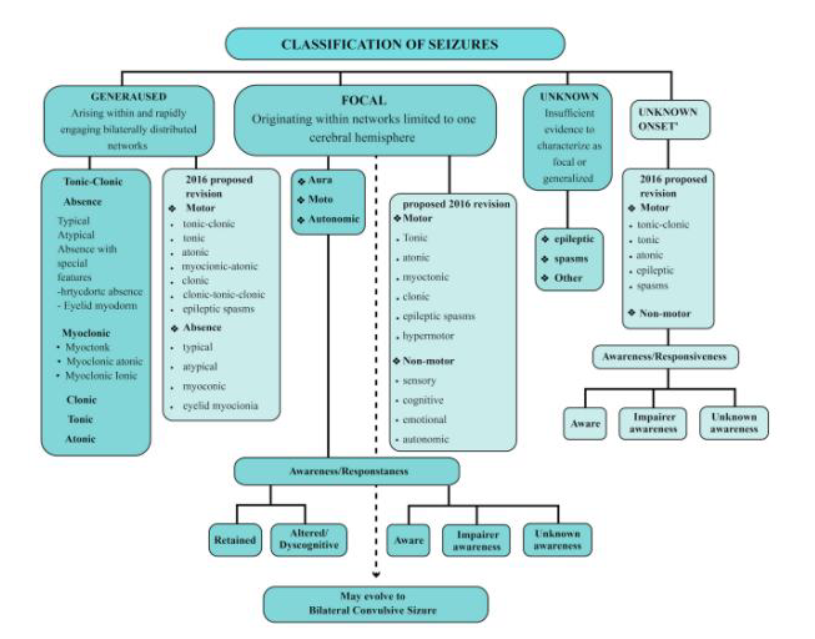
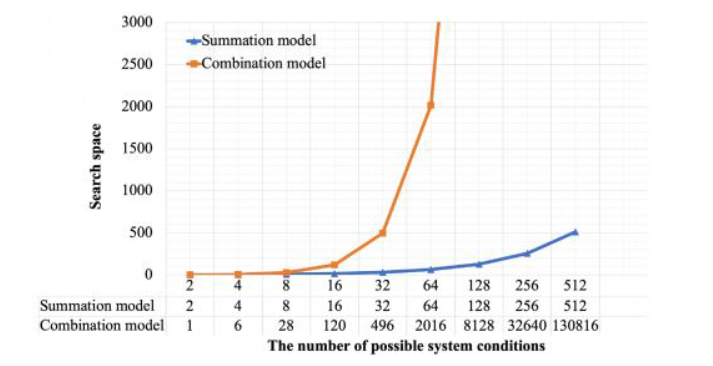
Seizures are a widespread condition affecting 50~65 million people in the world, and newborns are also susceptible to them. EEG is used to monitor the brain activity of newborns with suspected brain injuries, followed by a qualitative waveform interpretation by a group of clinical experts, where the means towards detection of seizures include a set of distinct characteristics in the waveform. This means of seizure detection has been critiqued, particularly due to subjectivity where, at times, waveform reviewing clinicians fail to reach a consensus on the presence of seizure activity in the brain of a newborn. As a means towards dealing with this problem, the author investigated the use of Artificial Intelligence-driven prediction machines capable of an automated diagnosis of seizure, based on a newborn’s EEG waveform. This approach used a reduced selection of EEG electrodes, the Linear Series Decomposition Learner (LSDL), an ensemble of a group of features, and performance comparison across multiple classification models. Secondary work was also carried out, which leveraged the patient information available alongside the EEG dataset. This involved the use of EEG towards predicting the level of asphyxia within the neonatal brain. The results from the seizure prediction exercise showed an increment in prediction performance of the seizures when preprocessed with the LSDL. The results spanned a range of figures (depending on the classification model), with the highest accuracy of 88.1%, while a probabilistic approach towards predicting the extent of seizures provided a maximum accuracy of 93.5%. The results from the secondary analysis showed a maximum accuracy for asphyxia prediction of 89.1%. The obtained results have helped to demonstrate that a reduced selection of electrode segments, alongside the selected algorithms, can serve towards the prediction of seizures for newborns within a neonatal intensive care unit.

 614 (Views)
614 (Views)  328 (Downloads)
328 (Downloads)